
As boas práticas com Git & GitHub
Como muitos já sabem, o Git é um sistema (gratuito) poderosíssimo para o controle de versões de um projeto. Nele, é possível criar e gerenciar várias versões de um mesmo projeto, em que as mudanças feitas são hospedadas em um servidor local ou remoto, como por exemplo o GitHub, que é o servidor que vamos considerar neste post.
Podem fazer parte de um projeto duas ou mais pessoas - geralmente, quanto maior e mais complexo é o projeto, mais pessoas o compõem -, e seguir “regras de etiqueta” para o versionamento de código pode ser fundamental para evitar que alterações indesejadas coloquem tudo a perder.
Por essa razão, a proposta deste escrito é mostrar algumas práticas simples para se trabalhar em grupo (ou mesmo individualmente) nas plataformas Git e GitHub, de modo a contribuir para um fluxo de trabalho eficiente e produtivo e também para o bom convívio entre os membros de equipe. Vale dizer que a ideia aqui não é ensinar a usar essas ferramentas. Para isso, no post Como trabalhar em grupo sem sofrer com o controle de versões você pode ter uma boa ideia em como o fazê-lo.
Bom, sem mais delongas, vamos às boas práticas!
Vamos partir do ponto que o projeto já existe, seja criado ou clonado. Na linguagem do GitHub, projetos são conhecidos como repositórios, e estes podem ser públicos ou privados. Normalmente, quando os dados a serem utilizados não podem ser divulgados, opta-se pelo repositório privado (aqui já está a primeira boa prática). No site do GitHub, dentro do repositório, a visiblidade pode ser facilmente configurada na opção Settings > Options > Danger zone > Change repository visibility.
Ainda na interface do repositório, conseguimos ver a disposição do
projeto. Para que você e outros usuários tenham melhor acessibilidade e
panorama acerca do projeto é sugerido que cada parte esteja alocada em
um diretório (pasta) - para aqueles viciados em organização, essa parece
ser uma dica primordial. No repositório exemplificado, os dados estão em
data/ e os códigos, em script/ (onde cada modelo, de predição e
interpretação, foi contemplado por uma pasta). Os resultados, neste
caso, em forma de gráficos e saídas de modelos, podem, futura e
satisfatoriamente, serem postos numa pasta denominada result/, por
exemplo.
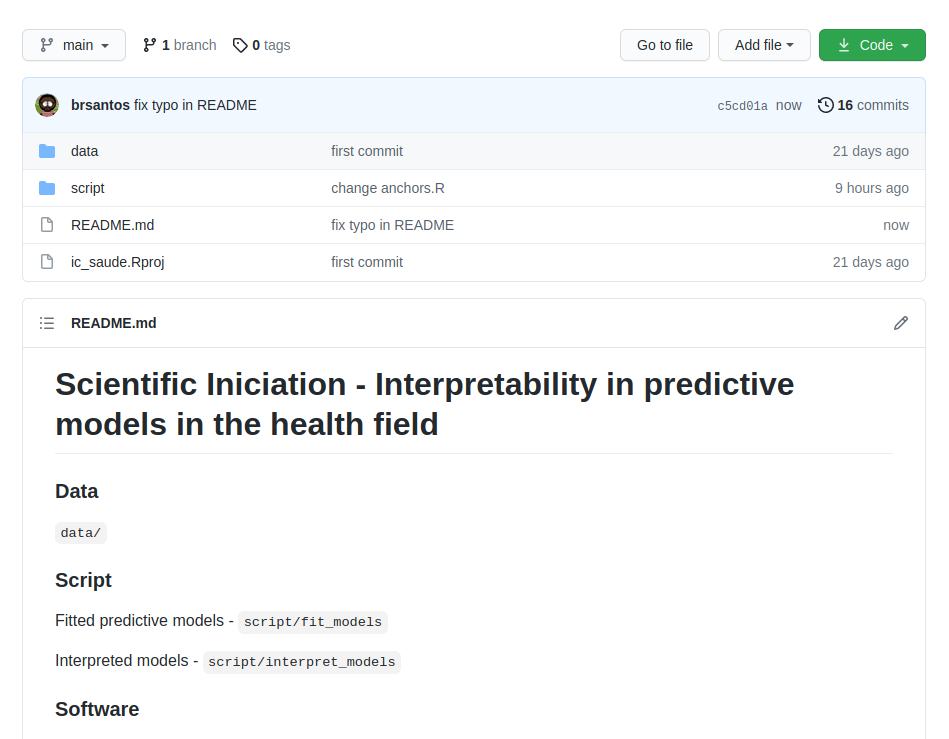
Sabemos que a finalidade central do GitHub é permitir que usuários da plataforma contribuam em quaisquer projetos liberados para tal. E por isso, é necessário sabermos do que se trata cada projeto. Quando acessamos um repositório, encontramos sua descrição no arquivo README e também no campo About, localizado no canto superior à direita.
Se você é o criador do projeto, em About, a descrição deve ser feita de forma bastante sucinta. Então economize nas palavras, mas sem perder a objetividade. Além disso, é possível incluir tópicos, que funcionam como as hashtags das redes sociais. Dessa forma, por meio desses rótulos, a tarefa de encontrar trabalhos com temas de interesse se torna muito mais fácil.
Já o documento README, um arquivo do tipo markdown, é o cartão de visitas de um projeto. Sendo assim, ele deve ser escrito com base no propósito do seu projeto, sem se preocupar com regras que levem a um “README perfeito”. No entanto, explicar de forma breve sobre o que é, qual é ou quais são suas formas de aplicabilidade e direcionar os locais onde se encontram cada parte do projeto já garante um README com qualidade. Ademais, arquivos README também podem agir como o status do projeto. Portanto, caso não haja a intenção de novas atualizações, você já pode deixar isso bem claro no README.
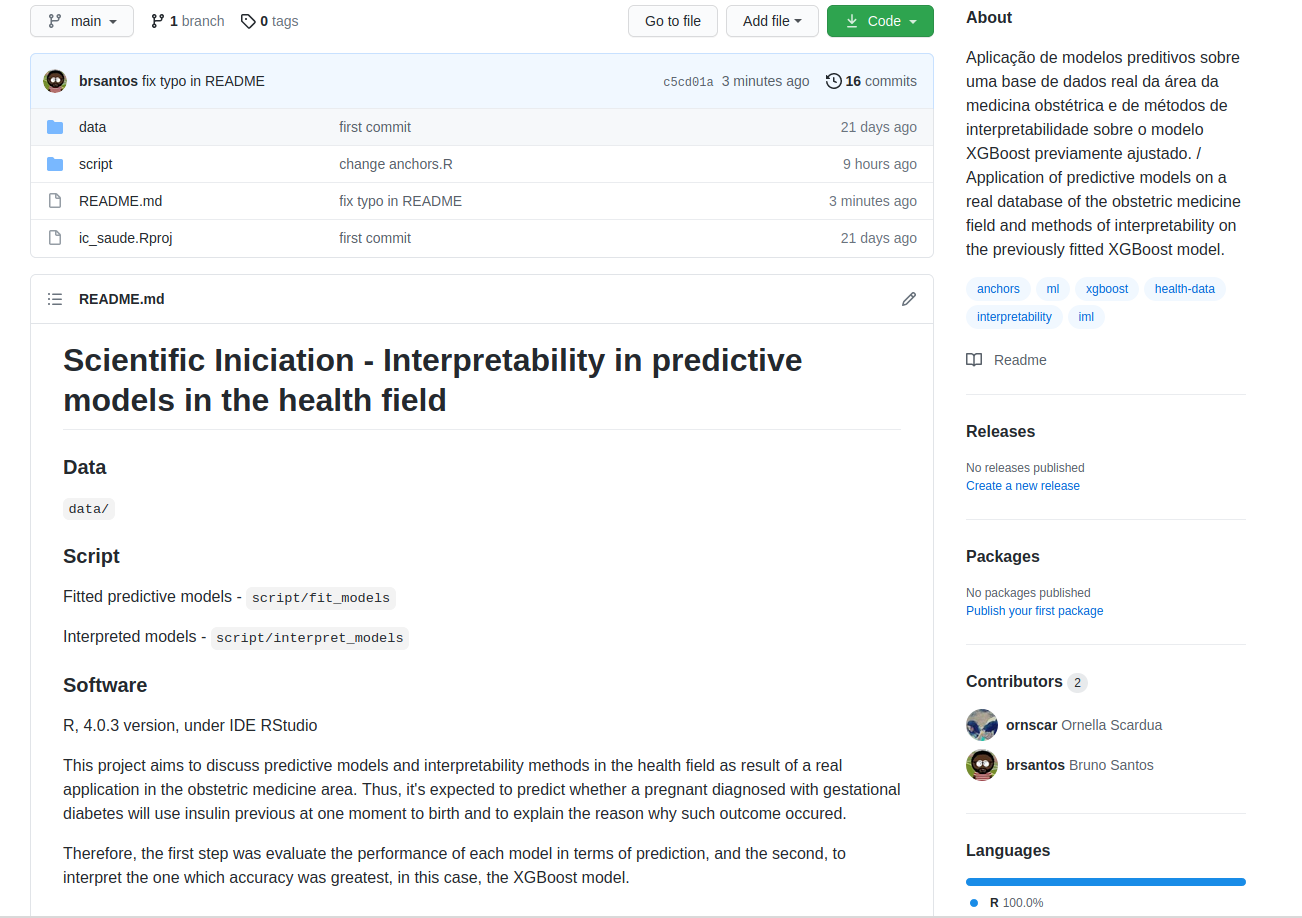
Lembre-se que os usuários do GitHub são e estão em toda parte do mundo. Logo, é mais interessante que tanto o About como o README estejam no idioma inglês, principalmente se o seu repositório for aberto.
Com o repositório em sua máquina e devidamente organizado no GitHub, podemos dar início às recomendações relacionadas diretamente ao Git.
Se o projeto é mantido por mais de uma pessoa e/ou se você está
trabalhando em duas máquinas diferentes, de sua casa e do seu trabalho
como exemplo, é aconselhável executar o comando $ git pull antes de
tudo. Posto que esse comando é responsável em trazer as alterações que
estão no GitHub para o seu repositório local, este passo é
imprescindível para impossibilitar, principalmente, a repetição, os
conflitos e a osciosidade de trabalho.
Outra maneira de começar um trabalho é executar o comando $ git
status, que, como o próprio nome já diz, indica o status atual do seu
repositório. A saída desse comando mostrará se há ou não arquivos não
rastreados pelo Git. Em caso negativo, deve-se executar $ git add <nome
do arquivo> ou $ git add * (neste caso, todos os arquivos são
adicionados em uma única vez) para que o(s) arquivo(s) seja(m)
mapeado(s) pelo Git e enviado(s) para o INDEX, local onde os
arquivos ficam armazenados até serem encaminhados para o GitHub.
Uma vez adicionados, os arquivos estão prontos para serem “commitados”.
Fazer $ git commit -m "<mensagem>" no Git significa criar uma espécie
de rótulo, com um número e um comentário, para os arquivos que estão no
INDEX. Esse talvez seja um dos principais processos em termos de
organização quando se está trabalhando com controle de versões, pois é
por meio de um commit que temos a ciência do que foi modificado ou
precisa ser consertado. Por esse motivo, seguir um padrão de commit é
recomendável. A saber.
-
se o repositório é público e/ou as pessoas envolvidas são de outra nacionalidade que não a brasileira, é preferível que a mensagem seja escrita em inglês;
-
no máximo em 50 caracteres;
-
use o verbo no imperativo, ou seja, em forma de ordem (“faça”, “corrija”, “conserte”, …); e
-
não use ponto final.
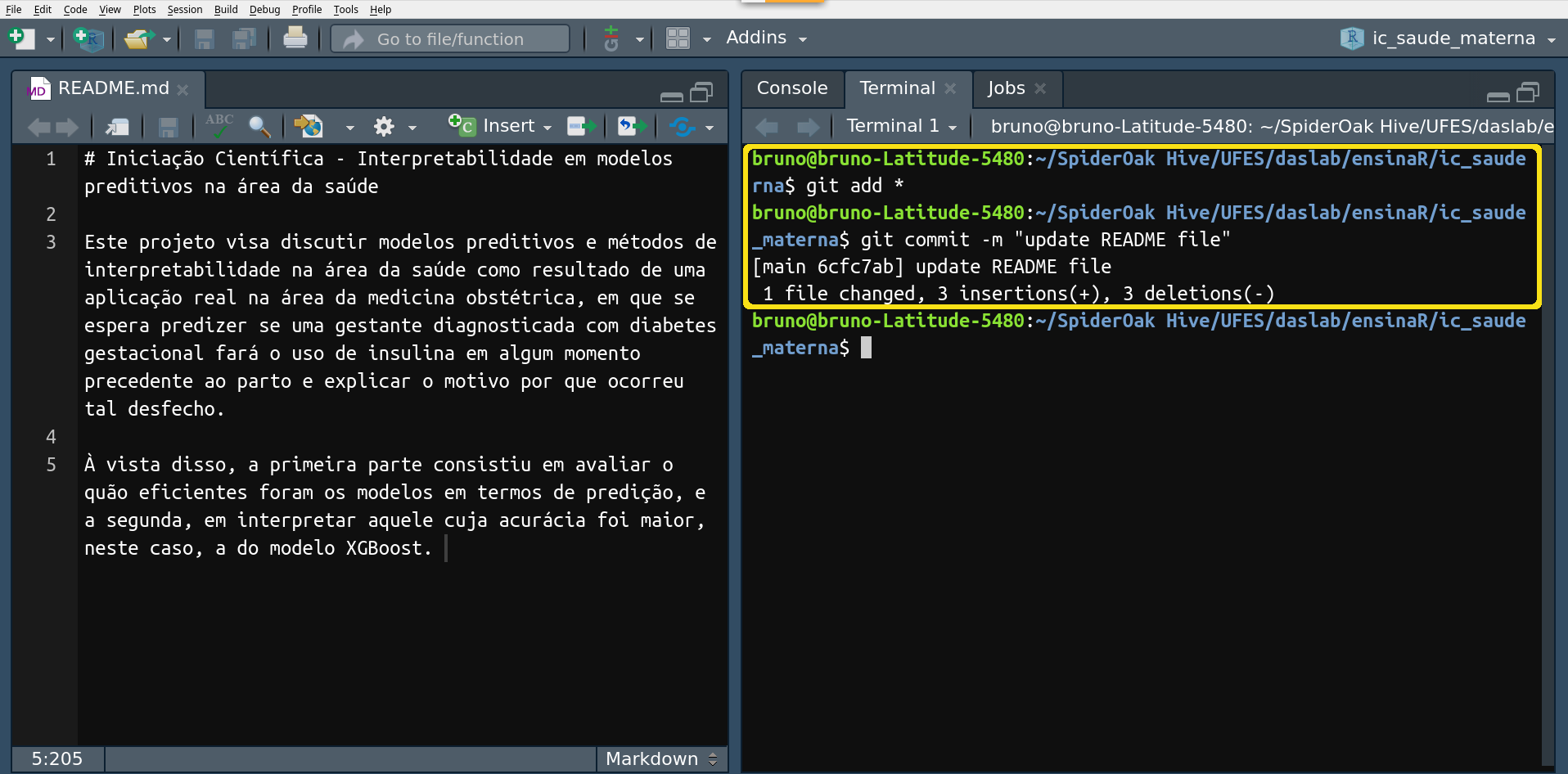
O ideal é que em um commit sejam feitas pequenas mudanças e que,
consequentemente, você “commite” sem pudor. Para mais, se correções
diferentes são realizadas, elas devem ser implementadas em commits
distintos, sendo, portanto, preferível usar $ git add <nome do
arquivo> a $ git add *. Ah, após “commitar” seus arquivos, não se
esqueça de executar $ git push -u origin main para publicá-los no seu
repositório do GitHub.
No cenário em que muitas pessoas fazem parte do projeto, é interessante
monitorar os commits que foram realizados. Para isso, basta executar
$ git log, que informará quanto à hash (identificador único), nome
do autor e data do commit. Dessa forma, facilmente identificaríamos um
commit de interesse.
Uma importante boa prática também está associada com a gestão de problemas, feita diretamente no site do GitHub, na aba Issues de um repositório, que é usada exclusivamente para reportar e discutir tarefas e bugs. A fim de que uma issue seja prontamente assimilada e indentificada, é indicado que sejam registradas algumas informações, tais como:
-
no Título, escreva de forma direta sobre o que é a issue;
-
na Descrição, descreva a issue de modo completo, detalhando as etapas que foram executadas até a ocorrência do problema, bem como o resultado equivocado e o resultado esperado da aplicação;
-
se necessário, anexe imagens ou documentos que auxilie na resolução da issue;
-
use (e abuse) das opções de formatação de texto;
-
mencione a @ do usuário para a qual a issue será direcionada;
-
crie uma lista de tarefas para melhor acompanhar o andamento da issue, caso ela seja grande e complexa;
-
rotule a issue de modo que o problema seja previamente identificável (você pode usar rótulos prontos ou mesmo criá-los); e
-
ao resolver uma issue, encerre-a.
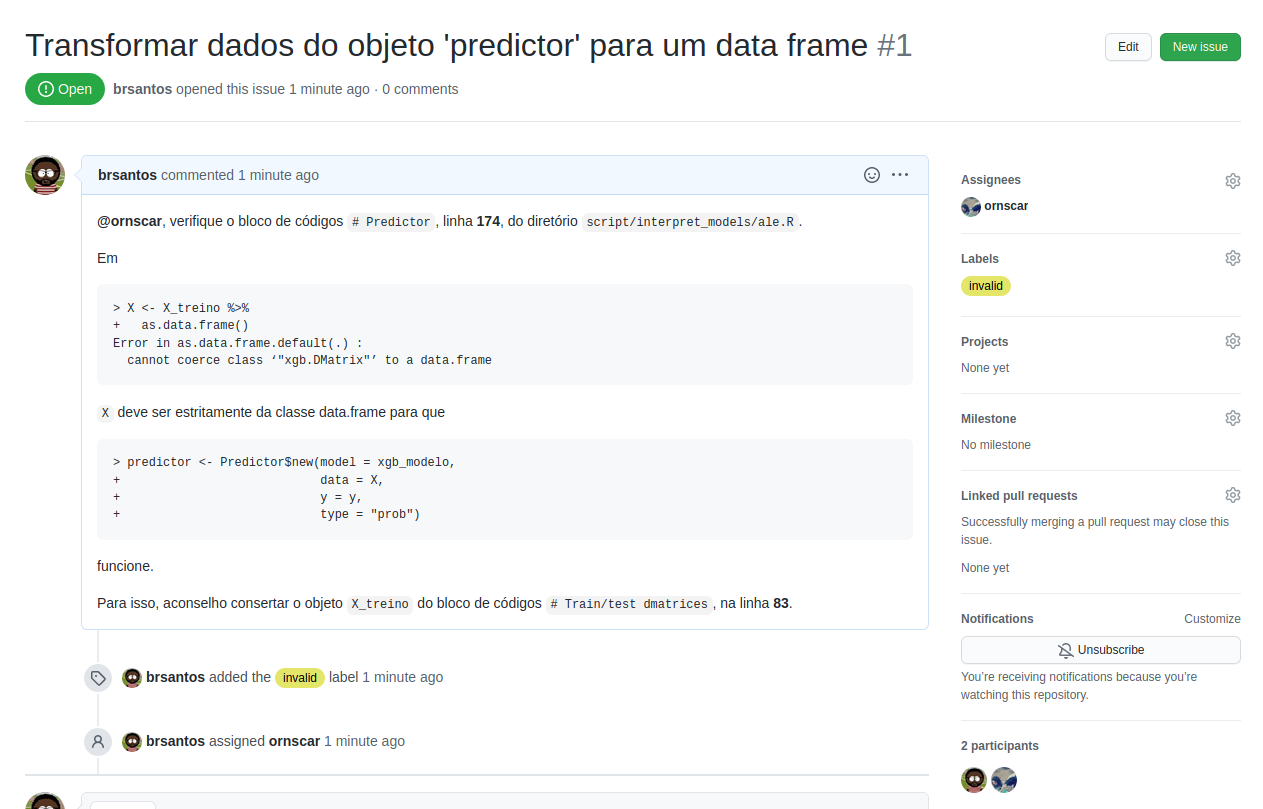
Para projetos maiores, outras dicas são aconselháveis, como especificar a versão do software programacional e do sistema operacional em que se manifestou o problema.
Outro conselho bastante valioso no que diz respeito às issues está em
como encerrá-las. No Git, algumas palavras atuam como verdadeiros
códigos, sendo as relacionadas a issues: fix, fixes, fixed,
close, closes, closed, resolve, resolves e resolved.
Portanto, para finalizar uma issue digite o código $ git commit -m
"fix error on issue #10", ou com qualquer uma das outras palavras
mencionadas no lugar de ‘fix’, em que ‘#10’ é a ID (o número que
aparece na URL ao acessar uma issue ) da issue a ser solucionada.
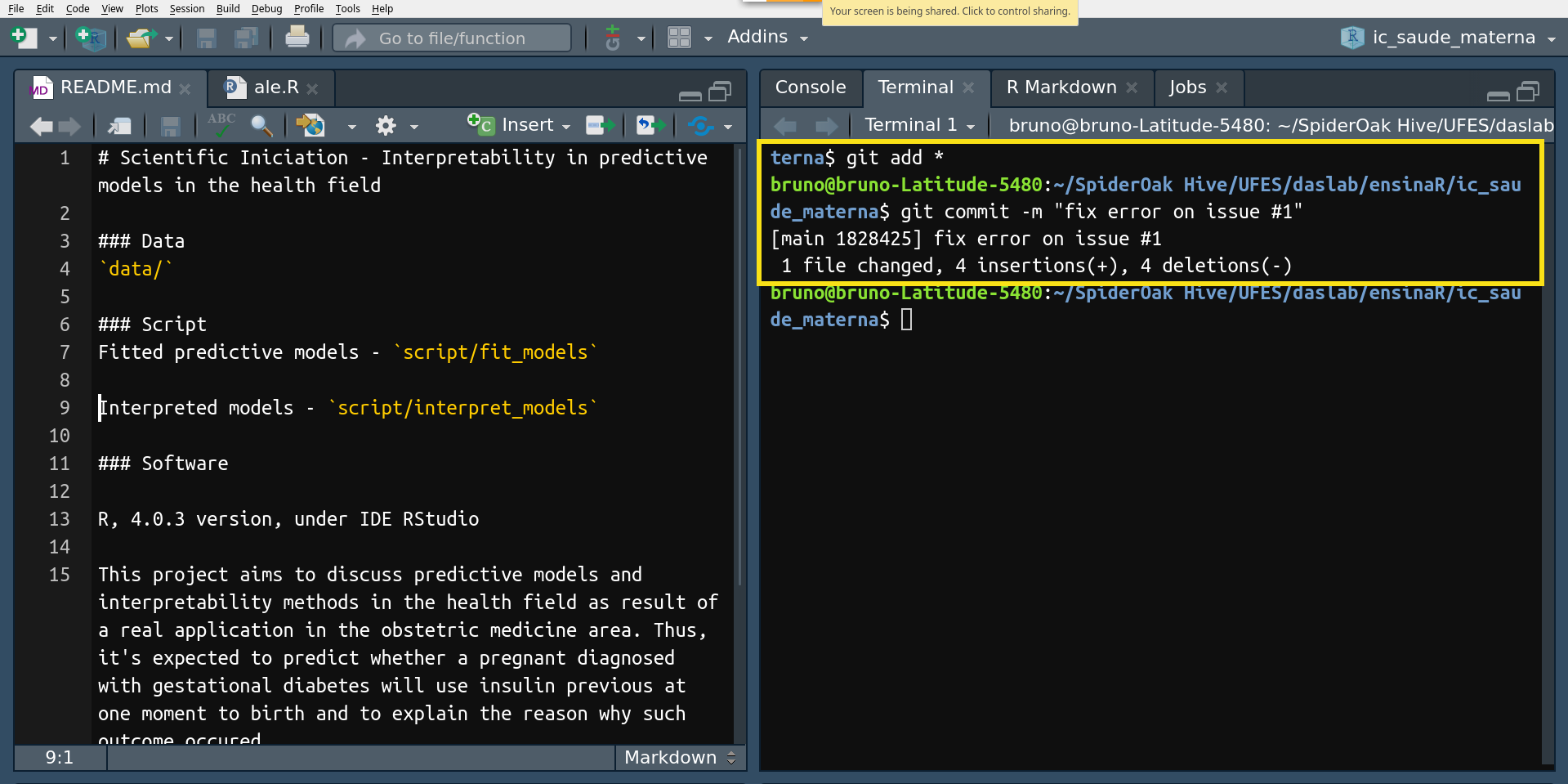
Outra forma de manter a organização de um projeto é utilizar tags, que
basicamente correspondem à versão atual do projeto. Você pode estar
pensando nos seus tempos de Word, não é? E você tá certo(a), é isso
mesmo. É a mesma coisa de quando tínhamos arquivos no Word e salvávamos
com os nomes “trab1.dcx”, “trab2.dcx”, …, “trab100.dcx”,
“naoaguentomais.dcx” e “finalmentechegouahoraobrigadodeus.dcx” à
medida que os editávamos. Aqui, a grande diferença é que não precisamos
ter essa grande dor de cabeça, apenas precisamos executar o comando $
git tag -a <nome da tag> -m <mensagem> para cada vez que quisermos
atualizar a versão de nosso projeto. Assim, sempre que iniciarmos um
novo trabalho é adequado verificar se estamos com a versão mais
atualizada do projeto. Em outras palavras, não se esqueça nunca do $
git pull.
Reparem que a sintaxe é bastante semelhante a de um commit.
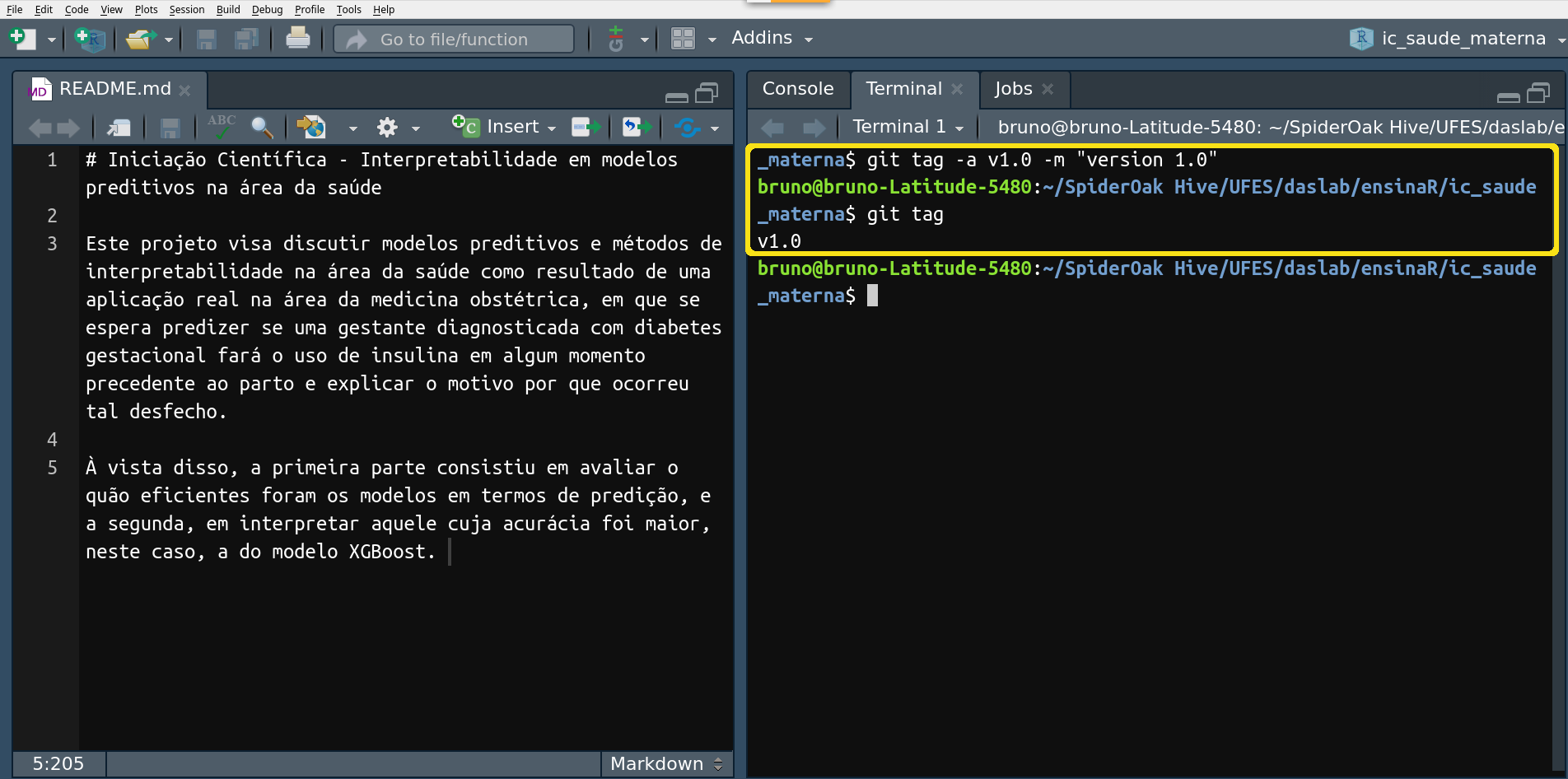
Até aqui, discutimos um fluxo de trabalho limitado somente ao ambiente
principal, vulgarmente chamado de branch main ou branch master no
mundo Git. Entretanto, quando o projeto envolve uma equipe muito grande,
o mais correto é criar ambientes separados de tal forma que cada novo
ambiente, ou branch, esteja associado a uma pessoa ou a um grupo de
pessoas. No Git é possível criar infinitas branches, mas vale o bom
senso para serem criadas uma quantidade que seja realmente relevante
para o projeto. Ao executar $ git checkout –b <nome da branch>, um
ambiente pararelo ao principal é criado (‘-b’ direciona para a nova
branch automaticamente). E $ git branch exibe todas os ambientes do
projeto.
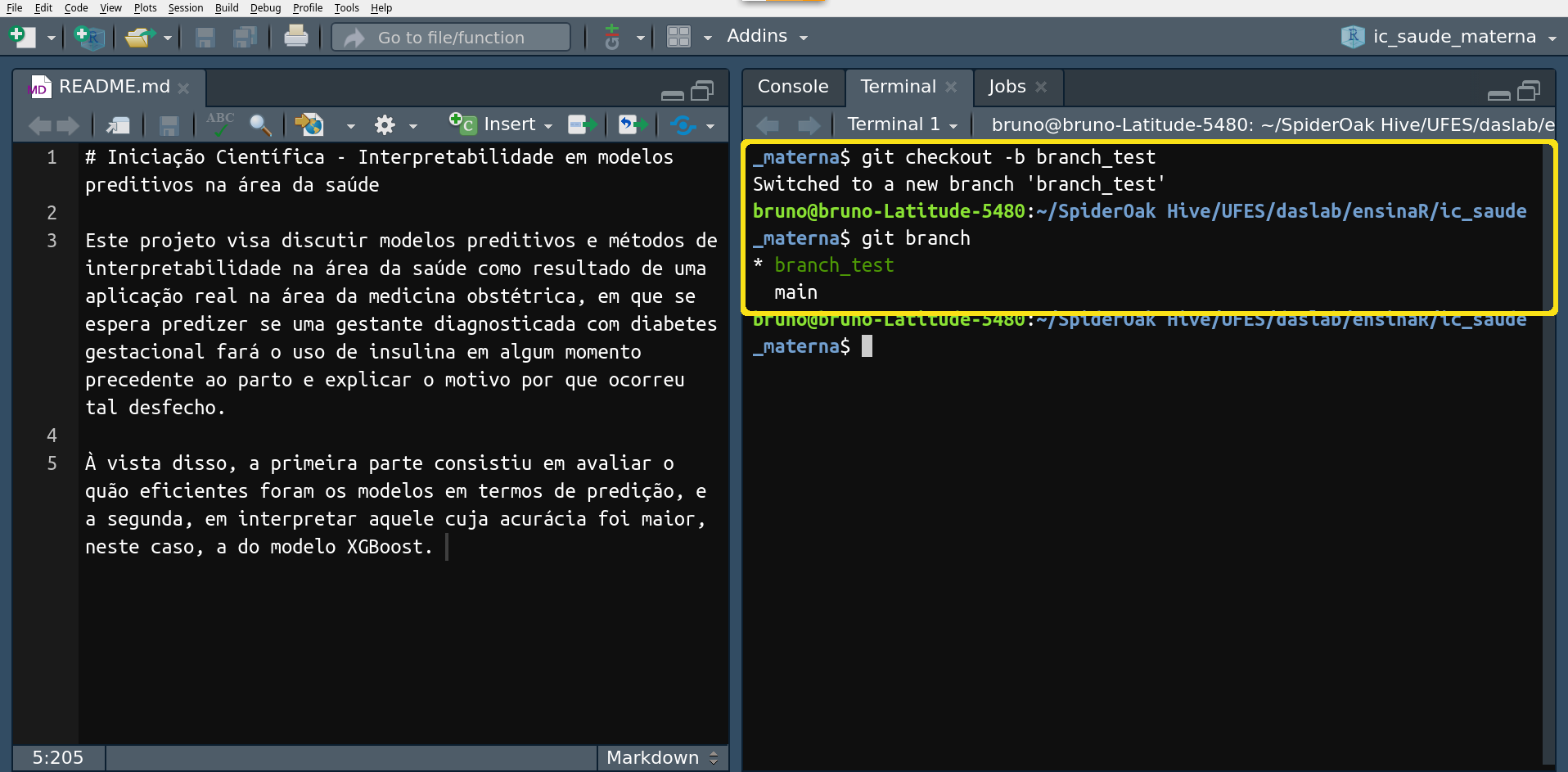
Para cada nova branch criada, as boas práticas são análogas. A
diferença é que vamos precisar conectar as branches secundárias à
branch main, isto é, atualizar a branch principal com as
modificações feitas em cada uma das outras branches. Basicamente, o
que precisamos fazer é retornar para a branch main por meio do comando
$ git checkout main e em seguida mesclá-la com uma outra branch na
qual houve modificações por meio do comando $ git merge <nome da branch
para mesclar>. Caso aconteçam conflitos de informações (quando algum
usuário fez um merge com uma versão antiga, por exemplo), o Git
informará e apontará quais as alterações ainda são necessárias.
ATENÇÃO! Mantenha sempre a branch principal atualizada.
O bloco de comandos destacado em vermelho mostra uma alteração feita na branch paralela (e um plus ao adicionar uma nova versão ao projeto). Já o bloco de comandos em amarelo exibe a junção de informações entre branches, de fato.
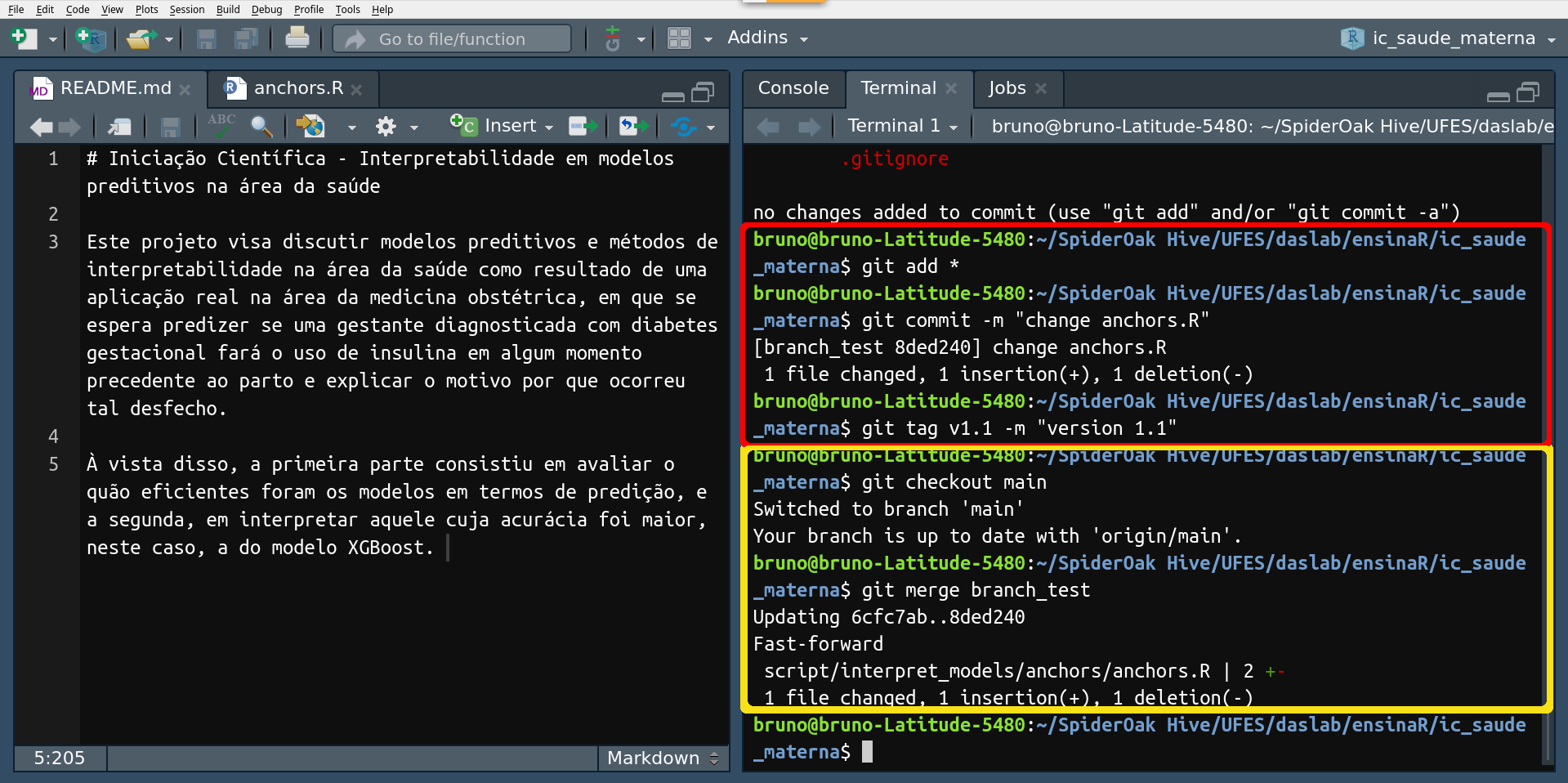
Agora que temos a branch master atualizada, você deve atualizar a
branch com a qual está trabalhando, já que provavelmente outros
usuários também fizeram um merge com a branch principal. Para isso,
execute $ git checkout <nome da branch> seguido de $ git rebase
main.
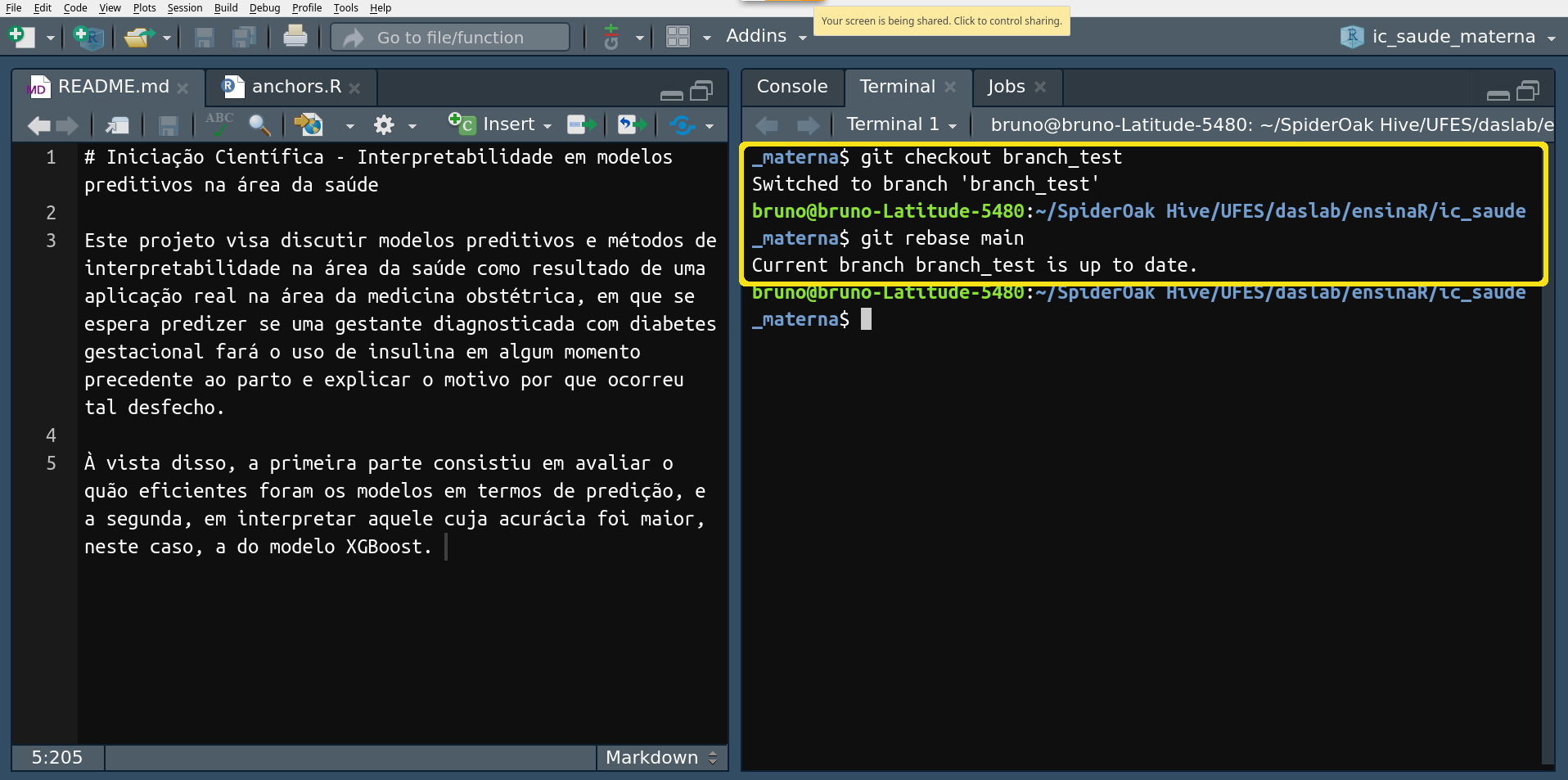
Pronto.
Podemos dizer que todas as branches e relações interpessoais estão harmonizadas e em perfeitas condições para que os trabalhos continuem da melhor maneira possível.
Antes de finalizar este post, vale lembrar que as boas práticas com Git e GitHub não serão de grande valia se você também não seguir as boas práticas com seus códigos. Aproveito, então, para deixar como sugestão o post Boas práticas no software R caso você queira saber mais sobre códigos “limpos” e bem estruturados sob a linguagem de programação R.
Hasta!