
Incrementando seus gráficos do ggplot2
Agora que já vimos os conceitos básicos do ggplot no post anterior, vamos mostrar um pouco como você pode aprimorar o seu gráfico de algumas formas como, por exemplo, adicionar legendas, alterar cores, posições, etc. Para isso vamos trabalhar com os gráficos mais utilizados:
geom_bar()/ geom_col(): gráfico de barras/ gráfico de colunas;box_plot(): box-plot;geom_histogram(): histograma;geom_point(): gráfico de dispersão;geom_line(): gráfico de linhas.- ``
Vale ressaltar que quando se trata de incrementar um gráfico, existem inúmeras maneiras de fazer isso. Vamos mostrar apenas algumas delas aqui e deixar alguns links ao longo do texto que se aprofundam no tema.
Vamos carregar inicialmente o pacote tidyverse, que carrega
automaticamente o ggplot2 e outros que possamos utilizar ao longo do
texto.
library(tidyverse)
library(MASS)
library(highcharter)
Gráfico de barras
position
Quando falamos em apresentar as informações no gráfico de barras,
podemos pensar em 3 possibilidades para o argumento position:
position = "stack", position = "fill" e position = "dodge".
Basicamente cada um desses irá apresentar as informações de formas
diferentes. Para mostrar isso vamos utilizar a base de dados Cars93 do
pacote MASS. Caso deseje utilizar essa base de dados e não tenha o
pacote instalado no seu computador, basta rodar o código
install.packages("MASS").
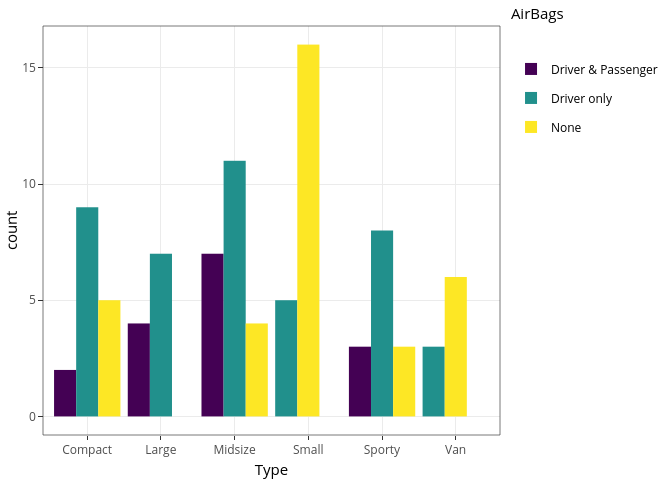
ggplot(Cars93, aes(x = Type, fill = AirBags)) +
geom_bar(position = "stack") +
scale_fill_viridis_d() +
theme_bw()
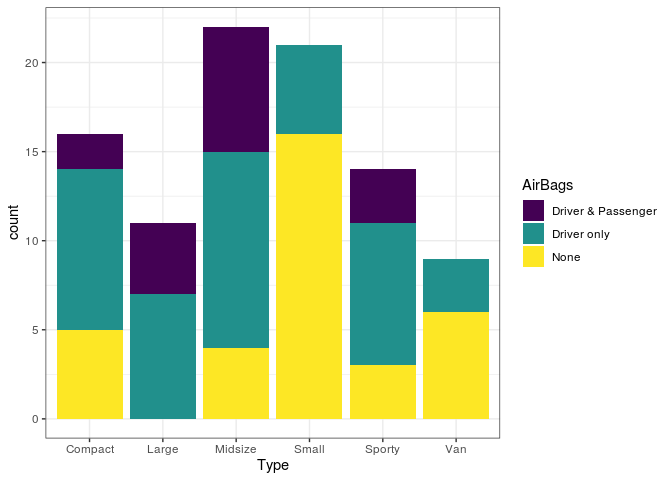
No gráfico acima utilizamos o position = "stack", que constrói o
gráfico de barras empilhado. Nesse caso, a contagem dos subgrupos são
exibidos apenas uns sobre os outros.
ggplot(Cars93, aes(x = Type, fill = AirBags)) +
geom_bar(position = "fill") +
scale_fill_viridis_d() +
theme_bw()
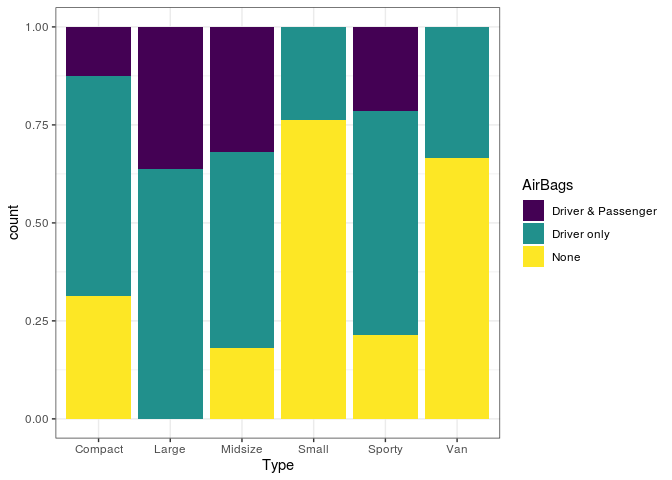
Quando utilizamos position = "fill", temos também as barras
empilhadas, porém cada barra tem altura constante igual a 1. Agora, a
porcentagem de cada subgrupo está representada, permitindo estudar a
distribuição de sua proporção no todo, para cada uma das barras.
ggplot(Cars93, aes(x = Type, fill = AirBags)) +
geom_bar(position = "dodge") +
scale_fill_viridis_d() +
theme_bw()
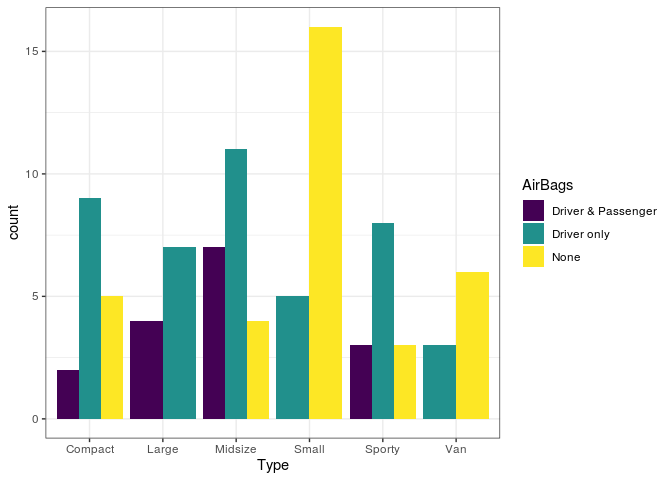
O caso position = "dodge" é um dos casos mais utilizados, pois ele irá
colocar as barras lado a lado. Normalmente, informações dessa forma
ficam mais fáceis de serem visualizadas. Porém, deve-se tomar cuidado
caso existam muitas categorias em uma das variáveis, o que pode tornar o
gráfico um pouco confuso. Caso isso aconteça pode ser interessante fazer
algumas modificações nos gráficos.
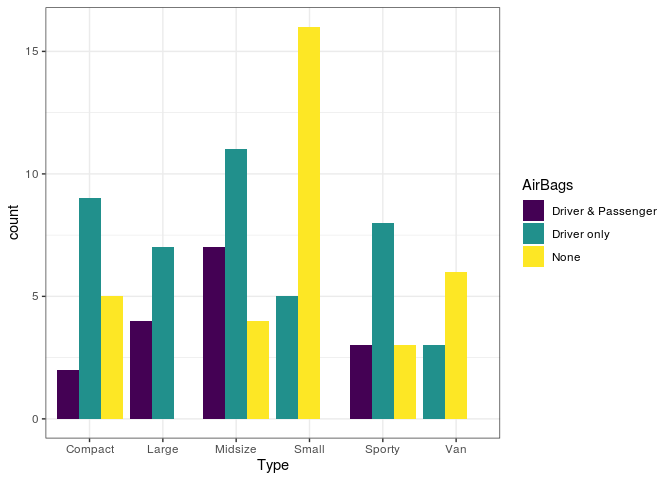
Observe o gráfico acima e note que algumas das barras possuem larguras
diferentes. O ggplot faz isso automaticamente quando alguma das
categorias está faltando, ou seja, ele deixa as barras mais grossas pra
compensar aquela que está ausente. Uma possível solução é utilizar
position = position_dodge(preserve = "single"). Veja:
ggplot(Cars93, aes(x = Type, fill = AirBags)) +
geom_bar(position = position_dodge(preserve = "single")) +
scale_fill_viridis_d() +
theme_bw()
Adicionando algumas informações
Frequência
Como dito acima, as vezes é interessante adicionar algumas informações aos gráficos para facilitar a visualização. Para o próximo exemplo vamos utilizar a base de dados diamonds contida no R.
dados_resumo2 <- diamonds %>%
group_by(cut, color) %>%
summarise(cont = n())
dados_resumo2 %>%
ggplot() +
geom_bar(aes(x = cut, y = cont, group = color, fill = color),
stat = "identity", position = "dodge") +
geom_text(aes(x = cut, y = cont, label = cont, group = color),
position = position_dodge(width = 1), size = 2.5,
vjust = 0.4, hjust = -0.1, angle = 0) +
coord_flip() +
theme_bw()
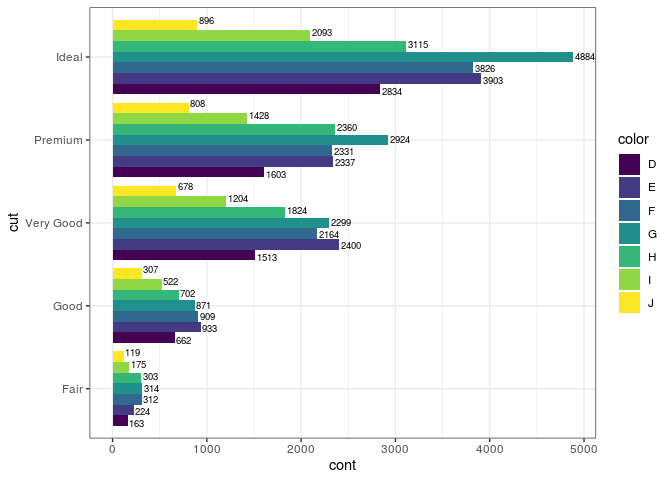
No gráfico acima adicionamos a frequência respectiva acima de cada
barra, fizemos isso com a ajuda do geom_text. Note que utilizamos o
position = position_dodge(width = 1). Diferentemente de quando usamos
position = "dodge" anteriormente, essa outra maneira nos permite
configurar algumas coisas como a largura, controlado pelo argumento
width. Nesse caso foi necessário usar para “configurar” a posição da
legenda. Também podemos “brincar” com outros ajustes como o vjust e
hjust que servem para mover a legenda verticalmente e horizontalmente.
Também temos o angle, que rotaciona as legendas quando você fornece o
ângulo desejado. Aqui também fizemos o uso do coord_flip() para
rotacionar os eixos do gráfico.
Porcentagem
dados_resumo <- Cars93 %>%
group_by(Type, AirBags) %>%
summarise(cont = n()) %>%
mutate(pct = prop.table(cont))
dados_resumo %>%
ggplot(aes(label = scales::percent(pct))) +
geom_bar(aes(x = Type, y = cont, group = AirBags, fill = AirBags),
stat = "identity", position = "dodge") +
geom_text(aes(x = Type, y = cont, group = AirBags),
position = position_dodge(width = .9), vjust = 0,
size = 2.3,
hjust = - 0.05) +
scale_fill_viridis_d() +
theme_bw() +
facet_wrap(~AirBags) +
theme(legend.position="none") +
coord_flip()
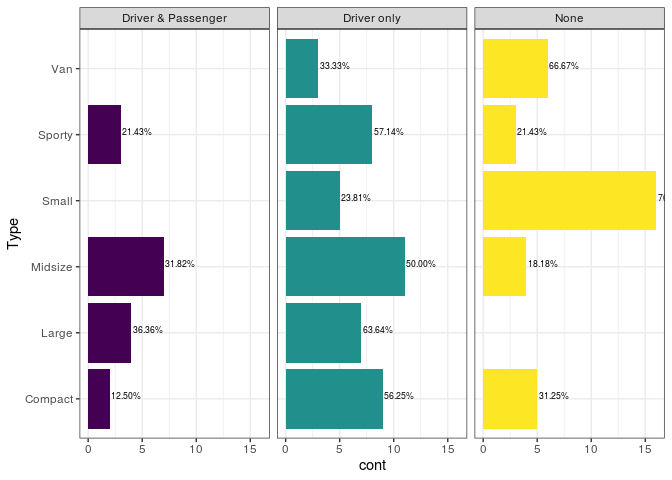
Também pode ser interessante em alguns caso adicionar a porcentagem
relativa em cada barra. Uma maneira de fazer e criar uma coluna no seu
banco de dados, que irá conter a porcentagem de cada observação em
relação ao total, é usando a função prop.table(), por exemplo. Agora
é só fazer parecido com o que fizemos anteriormente, passando as
coordenadas para o geom_text() e ajustando ao seu gosto pessoal. Aqui
precisamos adicionar também um label e para isso utilizamos a função
percent() do pacote scales.
Incrementando um Boxplot
Um gráfico comumente utilizado para visualizar dados é o Boxplot. Medidas de estatísticas descritivas como o mínimo, máximo, primeiro quartil, segundo quartil ou mediana e o terceiro quartil formam o boxplot. Ele também nos permite visualizar a distribuição e valores discrepantes (outliers) dos dados, fornecendo assim uma maneira rápida e fácil para entender um pouco melhor a distribuição dos dados. Podemos montar desde gráficos simples até alguns mais elaborados e esteticamente mais bonitos.
dfhair <- data.frame(HairEyeColor)
ggplot(dfhair, aes(x = Sex, y = Freq)) +
theme_minimal() +
geom_boxplot() +
geom_dotplot(
binaxis = 'y',
stackdir = 'center',
dotsize = 1,
binwidth = 2
) +
scale_x_discrete(labels = c("Homem", "Mulher")) +
xlab("Sexo") +
ylab("Frequencia")
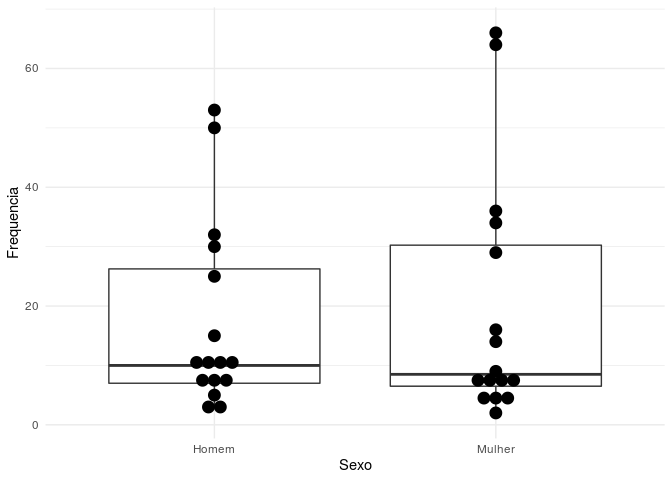
Aqui plotamos dois gráficos um ao lado do outro. Note que para fazer um
boxplot bem elaborado não é necessário adicionar muitas camadas. O que
pode ser novo aqui nessa visualização é a utilização de uma camada com
geom_dotplot(), com seus respectivos argumentos. Essa camada permite
adicionar um gráfico de pontos que combinado com o boxplot pode permitir
uma visualização mais completa dos dados. Você pode dar uma olhada mais
aprofundada em todos os argumentos do geom_dotplot() clicando
aqui.
ggplot(dfhair, aes(x = Sex, y = Freq,
fill = Sex)) +
theme_minimal() +
geom_boxplot(
outlier.colour = "black",
outlier.shape = 8,
outlier.size = 4
) +
scale_x_discrete(labels = c("Homem", "Mulher")) +
labs(
title = "Boxplot",
x = "Sexo",
y = "Frequência",
subtitle = "HairEyeColor",
fill = "Sexo"
) +
scale_fill_manual(values =
c("darkorchid4", "brown2"))
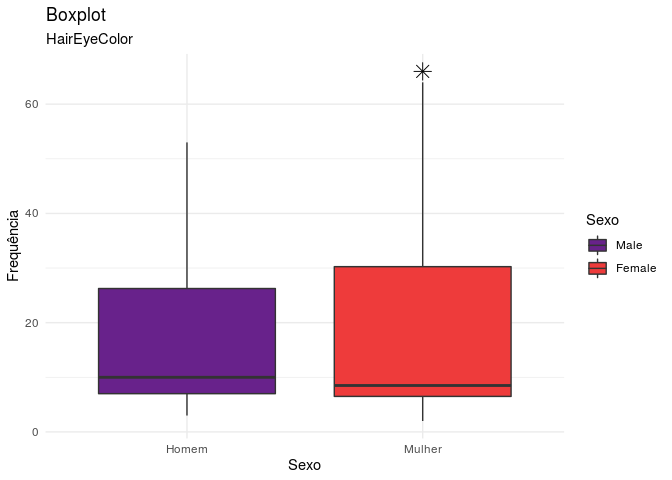
Caso prefira preencher os gráficos com cores da sua escolha, basta
alterar o color para fill dentro do aes e escolher a sua paleta de
cores preferida ou até mesmo utilizar scale_fill_manual para escolher
as cores de forma manual. Também utilizamos o labs para adicionar/
alterar algumas legendas do gráfico.
Histogramas um pouco mais elaborados
Fazer histogramas com mais de uma variável para comparação pode ser
interessantes em alguns casos. Para o exemplo abaixo vamos criar um
data.frame simples com duas variáveis geradas a partir da distribuição
normal.
da <- data.frame(
type = rep(c("variavel 1", "variavel 2"), each = 1000),
value = c(rnorm(1000), rnorm(1000, mean = 4))
)
da %>%
ggplot(aes(x=value, fill=type)) +
geom_histogram(color="yellow",
alpha=0.75,
position = 'identity') +
scale_fill_manual(values = c("darkorchid4", "brown2")) +
theme_bw() +
labs(fill = "")
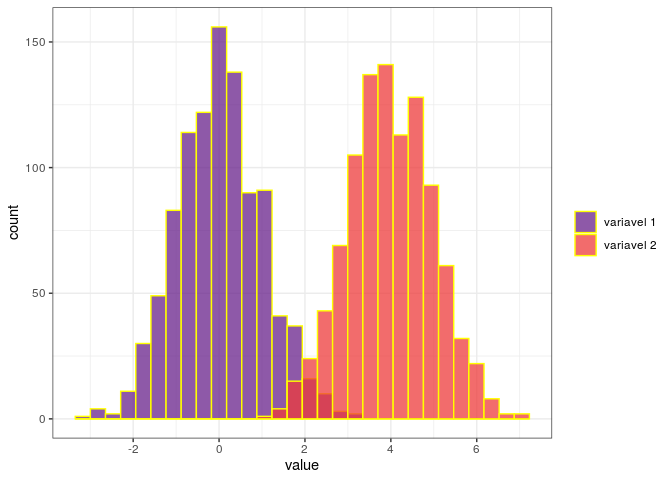
Um argumento legal capaz de nos ajudar na visualização dos gráficos em
alguns casos é o alpha. O alpha se refere à opacidade de um formato
geométrico. Os valores alpha variam de 0 a 1, com valores mais baixos
correspondendo a cores mais transparentes. color muda o contorno das
barras dos gráficos, o que pode nos ajudar também na diferenciação dos
gráficos quando eles se cruzam.
Uma outra forma de apresentar a mesma informação, porém sem que os gráficos se “cruzem” é utilizar uma faceta para cada um dos gráficos.
da %>%
ggplot(aes(x = value, fill = type)) +
geom_histogram(colour = "grey75") +
facet_wrap(~ type) +
scale_fill_viridis_d() +
theme_bw() +
labs(fill = "")
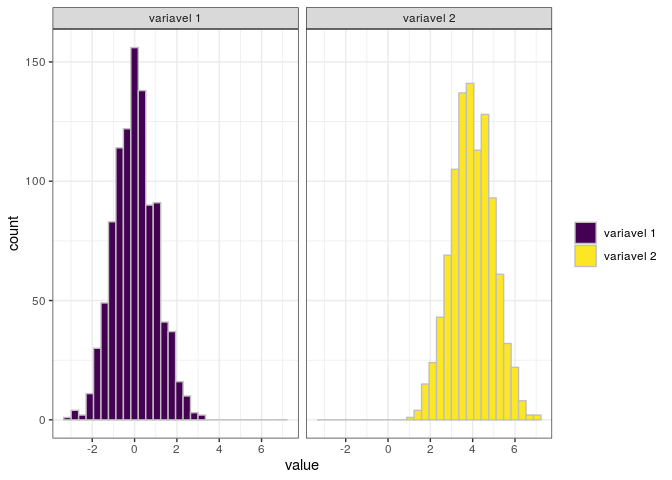
Ainda sobre histogramas, podemos considerar outros argumentos importantes dentro de cada faceta para apresentar o gráfico de diferentes formas. Veja o seguinte exemplo:
ggplot(diamonds, aes(x=price)) +
geom_histogram() +
facet_wrap(~ cut, scales = "free", ncol = 2) +
theme_bw()
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
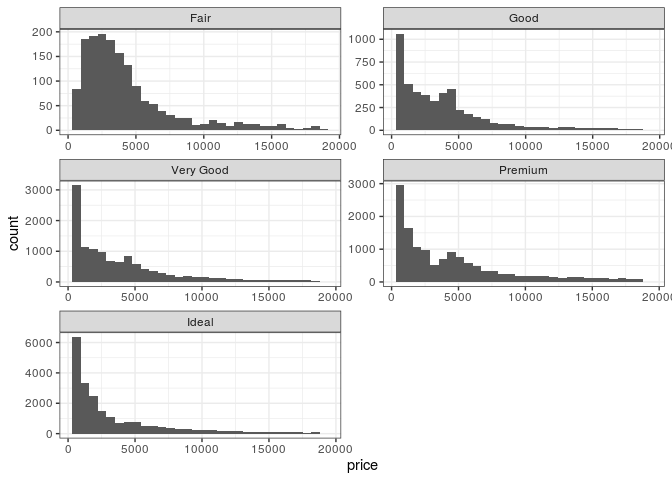
Note que aqui utilizamos scales = "free" para permitir que as escalas
de cada gráfico fiquem livres, ou seja, as escalas tanto no eixo x
quanto no eixo y podem ter valores diferentes para cada gráfico. Abaixo
vamos plotar o mesmo gráfico sem esse argumento apenas para comparação.
É importante tomar cuidado com isso quando for comparar os gráficos e
lembrar que eles possuem escalas diferentes entre si. Ainda sobre os
argumentos, utilizamos o ncol para determinar a quantidade de colunas
para os gráficos, porém também poderíamos determinar a quantidade de
linhas com o nrow.
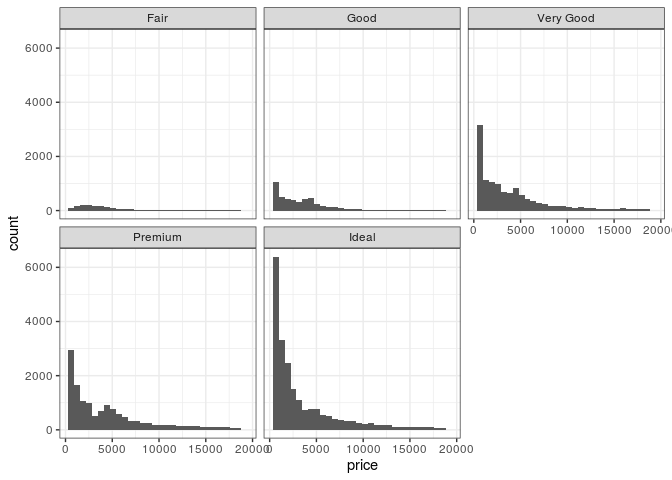
# exemplo sem scales = "free"
ggplot(diamonds, aes(x=price)) +
geom_histogram() +
facet_wrap(~ cut, nrow = 2) +
theme_bw()
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
É possível utlizar o facet_grid para comparar distribuições de
combinações de duas variáveis, considerando ainda histogramas. Veja o
seguinte exemplo:
ggplot(diamonds, aes(x = price, y = ..density..)) +
geom_histogram(fill = "darkviolet") +
facet_grid(color ~ cut) +
theme_bw()
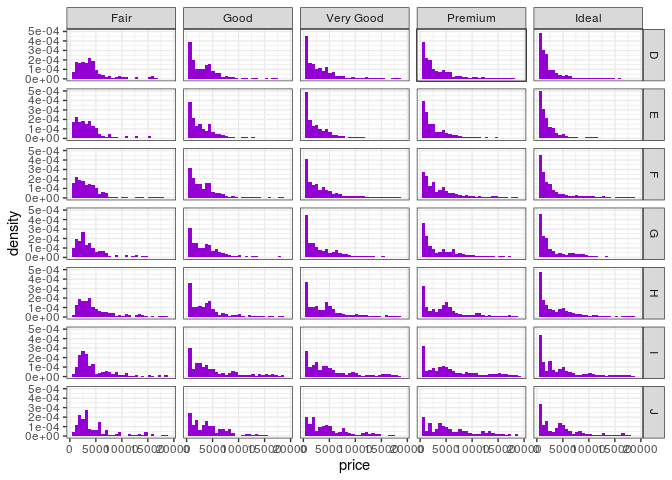
Veja como utilizamos o argumento y = ..density.. para considerar a
densidade das barras em cada um dos gráficos, ao invés da frequência
absoluta.
Gráficos de dispersão
Gráficos de dispersão são bastante utilizados, principalmente para verificar alguma correlação entre as variáveis. Abaixo vamos plotar 3 gráficos de dispersão diferentes, mudando pequenos detalhes em cada um deles.
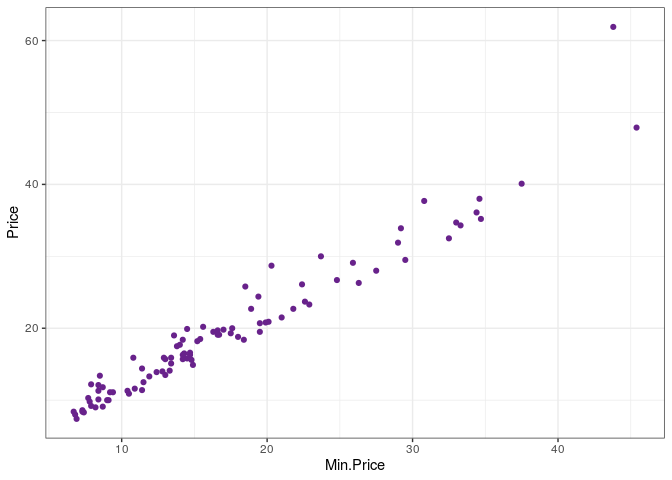
ggplot(Cars93, aes(Min.Price, Price)) +
geom_point(color = "darkorchid4") +
theme_bw()
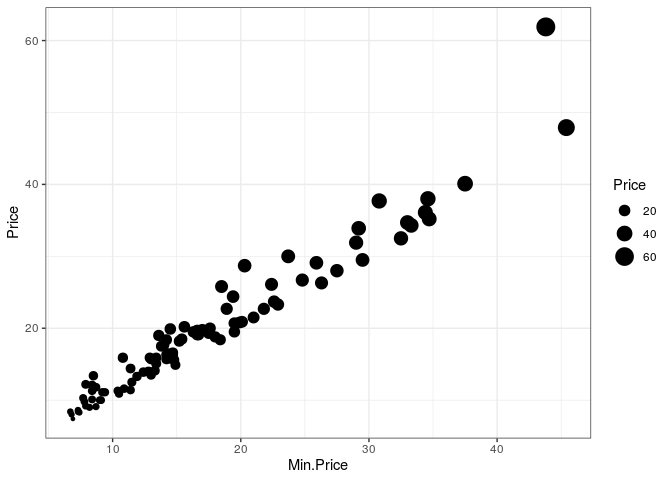
ggplot(Cars93, aes(Min.Price, Price)) +
geom_point(aes(size = Price)) +
theme_bw()
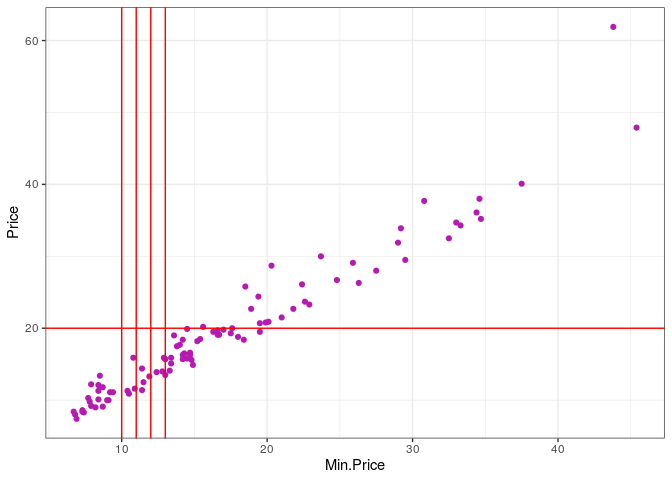
ggplot(Cars93, aes(Min.Price, Price)) +
geom_point(color = "#b51bb0") +
theme_bw() +
geom_vline(xintercept = 10:13, col="red") +
geom_hline(yintercept = 20, col="red")
O primeiro gráfico é bem simples, apenas alteramos a cor dos pontos e o
tema. No segundo gráfico utilizamos size = Price para alterar o
tamanho dos pontos de acordo com a variável Price. Esse argumento pode
ser muito interessante em alguns casos. No último gráfico mostramos a
possibilidade de adicionar algumas linhas verticais e horizontais no seu
gráfico por meio de geom_vline e geom_hline. Por exemplo, podemos
utilizar o geom_hline para colocar como argumento a média da variável
no eixo y e o geom_vline para plotar a média da variável no eixo x, da
seguinte forma.
ggplot(Cars93, aes(Min.Price, Price)) +
geom_point(color = "#b51bb0") +
theme_bw() +
geom_vline(xintercept = mean(Cars93$Price), col = "red") +
geom_hline(yintercept = mean(Cars93$Min.Price), col = "red")
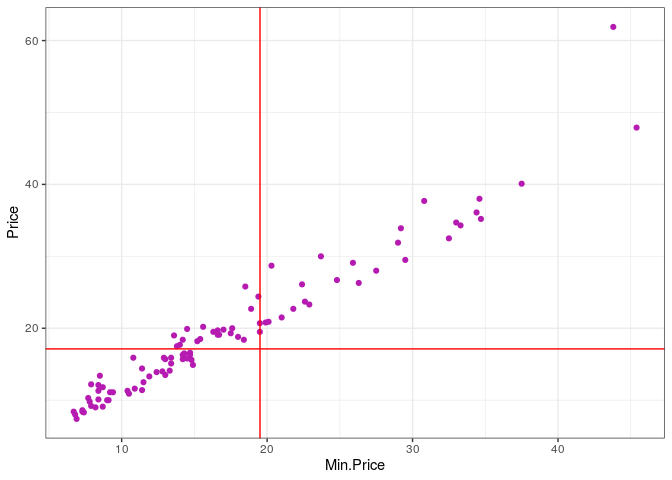
Veja como essas linhas nos permitem perceber uma certa assimetria nos dados, uma vez que estas não estão posicionadas bem no centro de cada eixo.
Gráfico de linhas
Vamos mostrar um exemplo simples de um gráfico de linhas utilizando
séries temporais e algumas maneiras de deixar ele mais elaborado. Para
isso, vamos reconsiderar os dados utilizados em um post anterior, sobre
os casos do novo coronavirus no Estado do Espírito Santo. Como no post
já mostramos detalhadamente como importar e utilizar os dados, vamos
pular essa etapa. Vocês podem acompanhar todas as instruções no seguinte
link. Uma pequena
observação a ser feita, no post deixamos um link para baixar
diretamente a base de dados, porém, o link mudou. Caso queira ter acesso
a base de dados basta clicar
aqui. Devido a isso,
os posts foram feitos com dados de períodos diferentes, podendo então
haver algumas divergências nos gráficos. Aqui nesse post consideramos
somente os valores a partir de 06/04/2021, para os quatro principais
municipios do Estado: Vitória, Vila Velha, Serra e Cariacica, salvos no
objeto dados_sumarizados_5, gerado a partir de uma base de dados que
havia sido obtida anteriormente à publicação deste post.
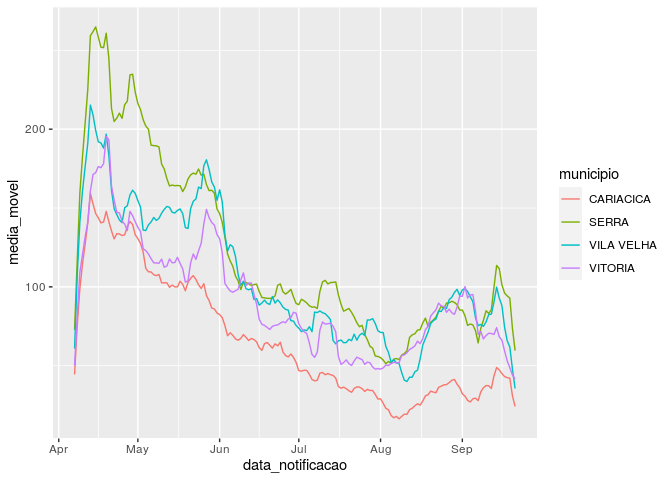
ggplot(dados_sumarizados_5,
aes(x = data_notificacao,
y = media_movel,
color = municipio)) +
geom_line()
ggplot(dados_sumarizados_5,
aes(x = data_notificacao,
y = media_movel,
color = municipio)) +
geom_line(linetype = "dashed") +
labs(
title = "Número de casos pela COVID-19 no ES",
subtitle = "Considerando somente Grande Vitória",
x = "Data",
y = "Número de casos",
caption = "Fonte: Painel COVID-19 Espírito Santo"
) +
theme_bw() +
theme(legend.position = "bottom") +
scale_x_date(date_breaks = "5 week")
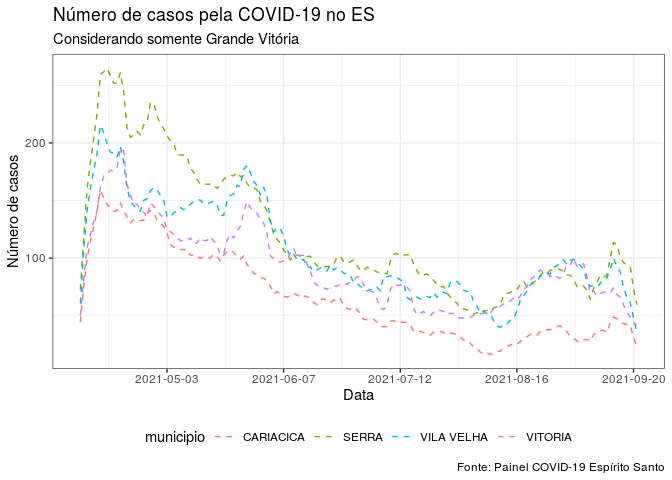
Note algumas diferenças do primeiro para o segundo gráfico, que podem
melhorar como algumas informações são apresentadas. No segundo gráfico,
usamos algumas novidades como o scale_x_date(date_breaks = "5 week")
que irá exibir as informações de 5 em 5 semanas. Fizemos também o uso do
argumento linetype que nos permite alterar o tipo da linha do gráfico.
São várias opções, você pode visualizar algumas neste
link
Uma observação a ser feita: ocultamos a parte do tratamento e separação
da base de dados pois já produzimos um post mostrando passo a passo como
fazer isso. Caso tenha interesse em reproduzir os resultados, basta ver
o post aqui.
Selecionando o período de tempo
Em alguns casos você pode querer selecionar apenas um intervalo de
tempo. Uma forma de fazer isso é utilizar o limit da função
scale_x_date() para selecionar um período de tempo nos dados.
Adicionar uma camada de geom_point aqui pode ajudar a perceber quando
há observações na série de valores, principalmente quando há uma
sequência de valores totalmente alinhados.
ggplot(dados_sumarizados_5,
aes(x = data_notificacao,
y = media_movel,
color = municipio)) +
geom_line() +
labs(
title = "Número de casos pela COVID-19 no ES",
subtitle = "Considerando somente Grande Vitória",
x = "Data",
y = "Número de casos",
caption = "Fonte: Painel COVID-19 Espírito Santo"
) +
theme_bw() +
geom_point() +
theme(legend.position = "bottom") +
scale_x_date(limit=c(as.Date("2021-04-22"), as.Date("2021-05-23")),date_breaks = "1 week")
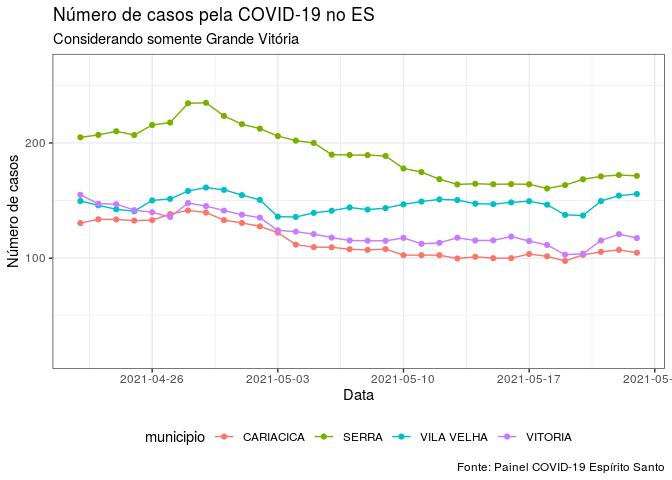
Vale ressaltar, que para gráficos de séries temporais, o eixo precisa
ser uma variável do tipo Date. Caso contrário, seria apenas um gráfico
de linhas.
Gráficos de calor
Considerando agora o objeto dados_todos, que foi construído de forma
semelhante ao que foi feito no post do pacote highcharter, com o link
compartilhado anteriormente nesse post aqui. Aqui consideramos a
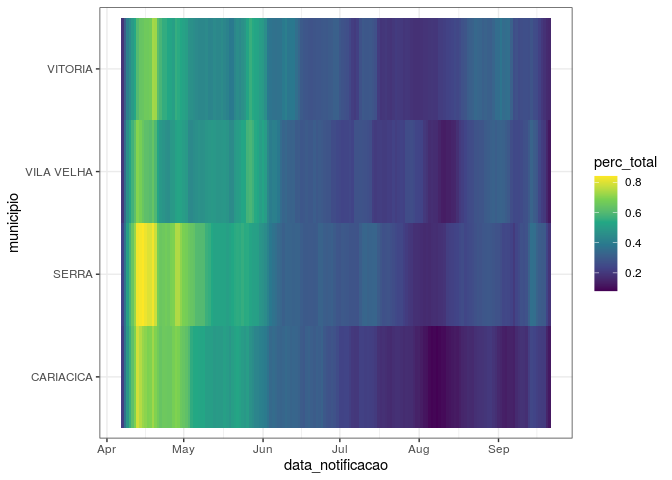
variável perc_total, que mostra o percentual do número de casos de
forma relativa ao pior momento da pandemia, para o período selecionado.
ggplot(dados_todos, aes(x = data_notificacao, y = municipio,
fill = perc_total)) +
geom_tile() +
theme_bw() +
scale_fill_viridis_c()
ggplot(dados_todos, aes(x = data_notificacao, y = municipio,
fill = perc_total)) +
geom_tile() +
theme_bw() +
scale_fill_viridis_c(option="inferno") +
labs(
title = "Número de casos relativo ao total observado na pandemia",
subtitle = "Número de casos dividido pelo maior valor de número de casos",
caption = "Fonte: Bovespa",
x = "Data da notificação",
fill = "")
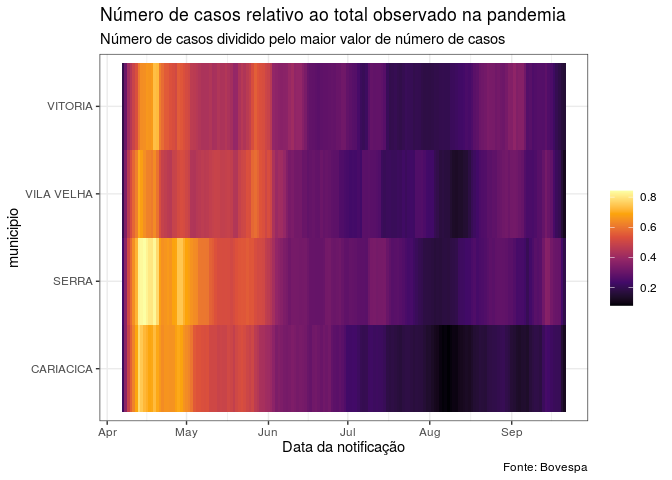
Acima fizemos dois gráficos de calor, um simples e o outro um pouco mais elaborado. Gráficos de calor podem ser difíceis de visualizar e por esse motivo pode ser interessante fazer o uso de gráficos interativos. Em seguida, vamos deixar algumas referências com relação a esse tópico.
Outras opções de pacotes para visualização de dados
Vamos deixar abaixo uma breve introdução de outros pacotes que você pode usar para plotar gráficos de maneira interativa ou animada. Não vamos nos aprofundar em nenhum deles, mas como mencionado no começo do post, vamos deixar alguns links para você ter acesso e buscar mais informações.
highcharter
o pacote highcharter serve para fazer gráficos interativos. Já fizemos
um post muito interessante para mostrar o uso desse pacote e você pode
acessar clicando aqui
aqui. Segue um spoiler
do que vai encontrar no post:
grafico6
plotly
O pacote plotly cria gráficos interativos da web a partir de gráficos
do ggplot. Uma maneira muito simples de usar o pacote é atribuir um
gráfico do ggplot a um objeto e plotar esse gráfico com o ggplotly.
Para esse exemplo vamos usar um gráfico que fizemos lá no comecinho do
post.
library(plotly)
pt <- ggplot(Cars93, aes(x = Type, fill = AirBags)) +
geom_bar(position = position_dodge(preserve = "single")) +
scale_fill_viridis_d() +
theme_bw()
ggplotly(pt)
https://operdata.com.br/blog/como-usar-o-pacote-plotly-no-r/
gganimate
gganimate é um pacote que permite a construção de gráficos animados.
Por exemplo, poderíamos construir um gráfico em formato de gifs ou
vídeos ilustrando alguns conceitos de distribuições de probabilidade
com mesma média e variâncias diferentes por exemplo. Também já fizemos
um post incrível sobre esse post, é só clicar
aqui.
Referências
https://operdata.com.br/blog/como-interpretar-um-boxplot/
https://www.r-graph-gallery.com/index.html
https://github.com/rstudio/cheatsheets/blob/master/data-visualization-2.1.pdf